Data Synchronization
INFO
🌐 This documentation has a Chinese translation.
This guide explores several optimal ways to synchronize (in other words, save and load) documents in BlockSuite.
Snapshot API
Traditionally, you might expect a JSON-based API that works somewhat like editor.load(). For such scenarios, BlockSuite indeed conveniently fulfills this need through its built-in snapshot mechanism:
import { Job } from '@blocksuite/store';
const { collection } = doc;
// A job is required for performing the tasks
const job = new Job({ collection });
// Export current doc content to snapshot JSON
const json = await job.docToSnapshot(doc);
// Import snapshot JSON to a new doc
const newDoc = await job.snapshotToDoc(json);The snapshot stores the JSON representation of the doc block tree, preserving its nested structure. Additionally, BlockSuite has designed an Adapter API on top of the snapshot to handle conversions between the block tree and third-party formats like markdown and HTML.
Document Streaming
Different from the classic mechanism above, BlockSuite natively supports a state management strategy that can be mentally paralleled with React Server Components. This allows the state of the block tree to be directly used as serializable data, streaming from the server (or local database) to the client.
In this case, the document data stored on the server is no longer JSON, but always a binary representation of CRDT (similar to protobuf or RSC payload). As the block tree in BlockSuite is natively implemented by CRDT, and the CRDT data is always updated first during state updates (see this article), the block tree state in the BlockSuite editor is always driven entirely by CRDT data. Therefore, compared to the RSC mindset:
ui = f(data)(state)The BlockSuite mindset is always:
ui = f(data)This is equivalent to updating the server first every time you update a todo list item, and then updating the state with the data returned from the server. However, with the ability of CRDT that automatically resolves conflicts, this process can be reliably completed locally and synchronized with remote documents.
In contrast, traditional editors typically only support APIs like editor.load(), which is more similar to a compromised f(data)(state) model, and has more complexity when dealing with real-time collaboration with multiple data sources.
In BlockSuite, the data-driven synchronization strategy is implemented through providers:
- When creating a new document, you only need to connect the
docto a specific provider (or multiple providers) to expect the CRDT data of the block tree to be synchronized via these providers. - Similarly, when loading an existing document, the method is to create a new empty
docobject and connect it to the corresponding provider. At this time, the block tree data will also flow in from the provider data source:
// IndexedDB provider from Yjs community
import { IndexeddbPersistence } from 'y-indexeddb';
// Let's start from an empty doc
const doc = createEmptyDoc();
// `doc.spaceDoc` is the underlying CRDT data structure.
// Here we connect the doc to the IndexedDB table named 'my-doc'
const provider = new IndexeddbPersistence('my-doc', doc.spaceDoc);
// Case 1.
// If you are creating a new doc,
// init here and the block will be automatically written to IndexedDB
doc.load(() => {
doc.addBlock('affine:page');
// ...
});
// Case 2.
// If you are loading an existing doc,
// simply wait here and your content will be ready
await doc.load();In both cases, whether the document is loaded or created, the doc.slots.ready slot will be triggered, indicating that the document has been initialized.
Furthermore, by connecting multiple providers, documents can automatically be synchronized to a variety of different backends:
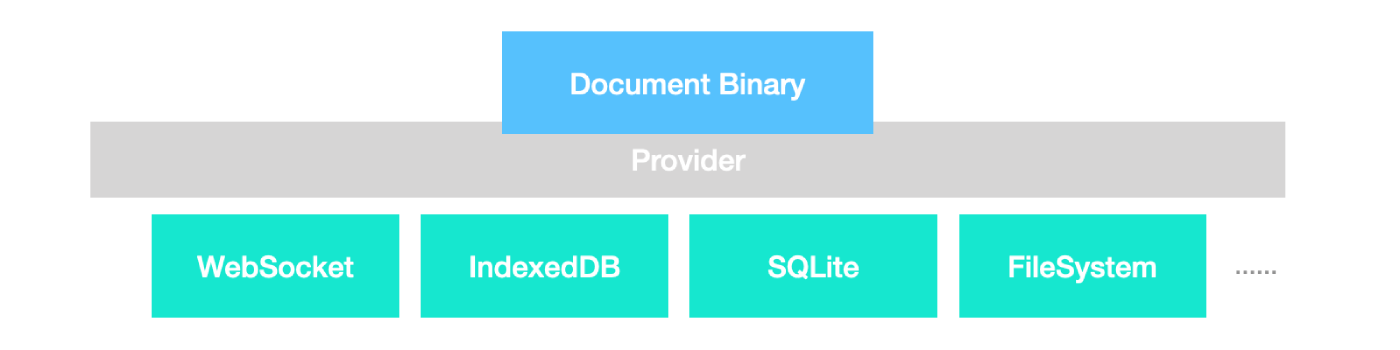
As an example, when testing real-time collabortion in BlockSuite following the steps, all the clients would connect to the WebSocket provider. The first client should enter case 1, and the clients joining the room afterwards would run into case 2.